SQL応用と正規化
データベース
GROUP BYで集計、正規化でテーブル分割!データベース設計の核心に迫ろう!
SQL応用と正規化
簡単にいうと
GROUP BYで集計、正規化でテーブル分割!データベース設計の核心に迫ろう!
① GROUP BY句とHAVING句
GROUP BY句は、指定した列の値が同じ行をグループにまとめ、グループ単位で集計を行うための構文です。
```sql
SELECT 部署コード, COUNT(*) AS 人数, AVG(給与) AS 平均給与
FROM 社員
GROUP BY 部署コード
```
GROUP BYと一緒に使う集合関数(集約関数)は以下の5つです。
| 関数 | 機能 | 使用例 |
|---|---|---|
| `SUM()` | 合計値 | `SUM(売上金額)` |
| `AVG()` | 平均値 | `AVG(給与)` |
| `COUNT()` | 件数 | `COUNT(*)` または `COUNT(列名)` |
| `MAX()` | 最大値 | `MAX(点数)` |
| `MIN()` | 最小値 | `MIN(価格)` |
`COUNT(*)`はNULLを含むすべての行をカウントしますが、`COUNT(列名)`はその列がNULLの行を除いてカウントします。この違いは試験で問われやすいポイントです。
HAVING句は、GROUP BYでグループ化した後に条件を指定するための構文です。WHERE句はグループ化の前に行を絞り込みますが、HAVING句はグループ化の後にグループを絞り込みます。
```sql
SELECT 部署コード, COUNT(*) AS 人数
FROM 社員
WHERE 入社年 >= 2020
GROUP BY 部署コード
HAVING COUNT(*) >= 5
```
この例では、まずWHERE句で2020年以降入社の社員に絞り、次にGROUP BYで部署ごとにグループ化し、最後にHAVING句で人数5人以上の部署だけを抽出しています。
② ORDER BY句・AS句・UNION句・CASE式
| 構文 | 機能 | 使用例 |
|---|---|---|
| `ORDER BY 列名 ASC` | 昇順(小→大)に並び替え。ASCは省略可能(デフォルト) | `ORDER BY 点数 ASC` |
| `ORDER BY 列名 DESC` | 降順(大→小)に並び替え | `ORDER BY 売上 DESC` |
| `AS 別名` | 列やテーブルに別名を付ける | `SELECT COUNT(*) AS 合計件数` |
| `UNION` | 2つのSELECT文の結果を縦に結合(重複排除) | `SELECT ... UNION SELECT ...` |
| `UNION ALL` | 2つのSELECT文の結果を縦に結合(重複保持) | `SELECT ... UNION ALL SELECT ...` |
| `CASE WHEN ... THEN ... END` | 条件に応じた値を返す | `CASE WHEN 点数>=80 THEN '合格' ELSE '不合格' END` |
ORDER BYはSELECT文の最後に書きます。複数の列を指定すると、先に書いた列を優先してソートします(例: `ORDER BY 部署コード ASC, 名前 ASC`)。
③ 正規化の3段階
正規化とは、データの重複や矛盾を排除するために、テーブルを段階的に分割していくプロセスです。
| 段階 | 名称 | 操作内容 |
|---|---|---|
| 第1正規化 | 繰り返しの排除 | 1つのセルに複数の値が入っている「繰り返し項目」を別テーブルに分離する |
| 第2正規化 | 部分関数従属の排除 | 複合主キーの一部にだけ依存している列を別テーブルに分離する |
| 第3正規化 | 推移的関数従属の排除+導出項目削除 | 主キー以外の列に依存している列を別テーブルに分離し、計算で求まる導出項目を削除する |
ステップバイステップの例で見てみましょう。
非正規形(元のデータ):
| 注文番号 | 顧客名 | 商品名1 | 単価1 | 数量1 | 商品名2 | 単価2 | 数量2 | 合計金額 |
|---|---|---|---|---|---|---|---|---|
| 001 | 田中 | ペン | 100 | 3 | ノート | 200 | 2 | 700 |
→ 商品が横に繰り返されている(1セルに構造的な繰り返し)
第1正規化後(繰り返しを排除):
| 注文番号 | 顧客名 | 商品名 | 単価 | 数量 | 合計金額 |
|---|---|---|---|---|---|
| 001 | 田中 | ペン | 100 | 3 | 700 |
| 001 | 田中 | ノート | 200 | 2 | 700 |
→ 繰り返しがなくなった。主キーは(注文番号, 商品名)の複合キー
第2正規化後(部分関数従属を排除):
「顧客名」と「合計金額」は注文番号だけで決まる(商品名に関係ない)→ これが部分関数従属。注文テーブルに分離する。
注文テーブル:
| 注文番号 | 顧客名 | 合計金額 |
|---|---|---|
| 001 | 田中 | 700 |
注文明細テーブル:
| 注文番号 | 商品名 | 単価 | 数量 |
|---|---|---|---|
| 001 | ペン | 100 | 3 |
| 001 | ノート | 200 | 2 |
第3正規化後(推移的関数従属の排除+導出項目削除):
「単価」は商品名で決まり、商品名は主キーの一部 → 推移的関数従属。商品マスタに分離する。「合計金額」は単価×数量から計算できる 導出項目 → 削除する。
注文テーブル:
| 注文番号 | 顧客名 |
|---|---|
| 001 | 田中 |
注文明細テーブル:
| 注文番号 | 商品名 | 数量 |
|---|---|---|
| 001 | ペン | 3 |
| 001 | ノート | 2 |
商品マスタ:
| 商品名 | 単価 |
|---|---|
| ペン | 100 |
| ノート | 200 |
④ 主キーと外部キー
テーブル設計において、データの一意性と整合性を保証する重要な概念です。
| 用語 | 意味 | 制約 |
|---|---|---|
| 主キー(Primary Key) | テーブル内の各行を一意に識別するための列(または列の組み合わせ) | 一意性制約(重複不可)+NOT NULL制約(空欄不可) |
| 複合キー | 複数の列を組み合わせて主キーとするもの | 組み合わせが一意であればよい |
| 外部キー(Foreign Key) | 他のテーブルの主キーを参照する列 | 参照制約(参照先に存在しない値は入力不可) |
外部キーにより、テーブル間のリレーション(関連性)が保証されます。たとえば、注文明細テーブルの「商品名」が商品マスタの主キーを外部キーとして参照していれば、商品マスタに存在しない商品名を注文明細に登録することはできません。
⑤ 正規化のメリットとデメリット
| 観点 | メリット | デメリット |
|---|---|---|
| データの一貫性 | データの重複が排除され、更新時の矛盾が発生しにくい | - |
| 整合性の確保 | 外部キーや制約により不正なデータの混入を防げる | - |
| 保守性 | テーブルが論理的に整理され、理解・変更しやすい | - |
| テーブル数 | - | 正規化するほどテーブル数が増加する |
| 検索性能 | - | 結合(JOIN)処理が増えるため、クエリの実行速度が低下する可能性がある |
このため、データ分析やレポート用途では、あえて正規化を緩めて(非正規化して)結合を減らし、検索性能を優先するケースもあります。
具体例
WHEREとHAVINGの使い分けを、成績データで確認しましょう。
「試験結果テーブル」
| 学生ID | 科目 | 点数 |
|---|---|---|
| S01 | 数学 | 85 |
| S01 | 英語 | 70 |
| S02 | 数学 | 60 |
| S02 | 英語 | 90 |
| S03 | 数学 | 45 |
| S03 | 英語 | 55 |
「60点以上の科目のみ対象で、平均75点以上の学生」を求める場合:
```sql
SELECT 学生ID, AVG(点数) AS 平均点
FROM 試験結果
WHERE 点数 >= 60
GROUP BY 学生ID
HAVING AVG(点数) >= 75
```
①WHERE: S03の数学(45)と英語(55)が除外される → S03は対象行なし
②GROUP BY: S01(85,70)→平均77.5、S02(60,90)→平均75.0
③HAVING: 平均75以上 → S01(77.5)とS02(75.0)が残る
WHEREは「個々の行」を絞り、HAVINGは「グループ化後の集計結果」を絞ります。この処理順序を正しく理解することが、SQL問題を解くカギです。
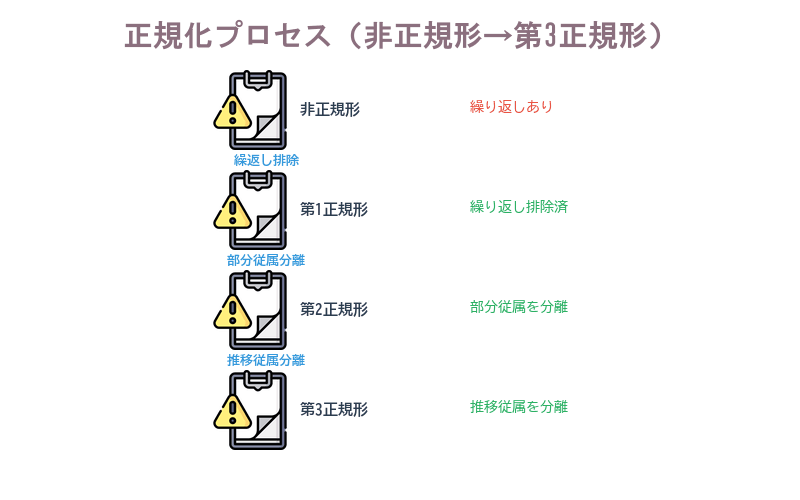
正規化プロセス(非正規形→第3正規形)
試験のポイント
- ・要は「第1=繰り返し排除、第2=主キーの一部への従属を分離(複合キー時)、第3=主キー以外への従属を分離+導出項目削除」
- ・GROUP BY+HAVING=グループ化後の条件指定、WHERE=グループ化前の条件指定
- ・COUNT(*)はNULL含む全行、COUNT(列名)はNULL除外も頻出
独学で診断士合格を目指すなら
過去問演習・AI添削・テキストPDFまで
すべて揃ったプレミアムプランで合格を掴む!
予備校代の1/10以下で、独学の不安をまるごと解決
- 📝1次試験 過去問演習(全7科目・年度別)無制限プレミアム限定
- 🤖2次試験 AI添削(事例I〜IV・無制限)最適なフィードバックで実力アッププレミアム限定
- 📄科目別テキストPDFダウンロード。印刷して好きな使い方で学習できるプレミアム限定
- 🔖ブックマーク機能で苦手分野・何度も確認したい部分を管理プレミアム限定
- 📊学習記録・成績管理で自分の進捗を可視化プレミアム限定
プレミアムプラン
¥9,800(税込)
自動更新なし / 1年間有効
決済は Stripe(PCI-DSS準拠)で安全に処理されます。カード情報は当サービスに保存されません。